Art x Public AI is a new research project by the Creative AI Lab, a collaboration between the Serpentine (a public arts org in London) and the Department of Digital Humanities, KCL. The lab focuses on developing research and prototypes that further artistic experimentation with AI. Our aim is to expand the conversations around AI by offering a more nuanced vision and approach to the negotiation of its public value and interest. Through the lens of art-making, we are able to explore key questions with greater precision and specificity.
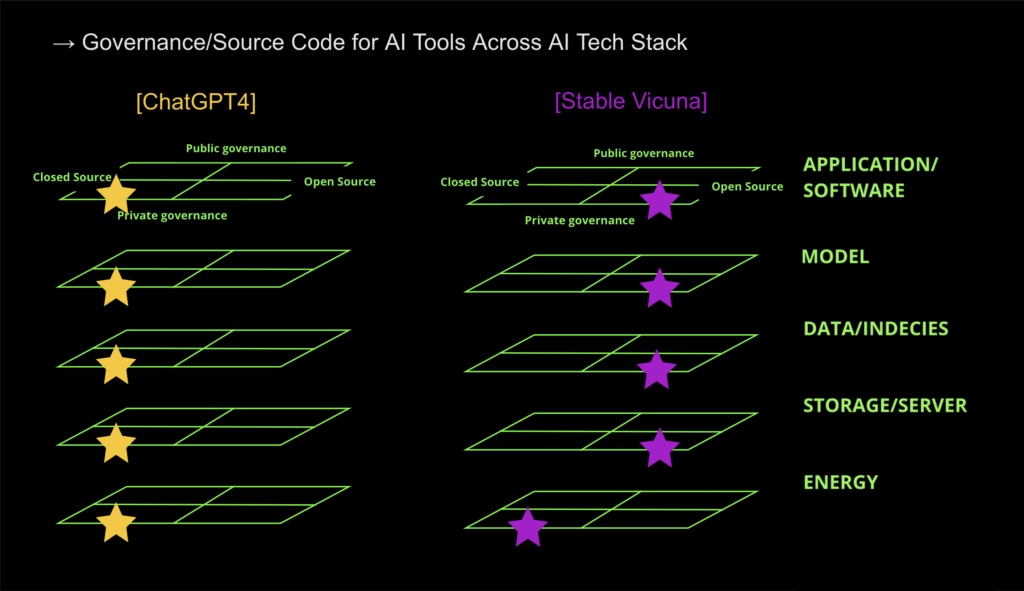
In our first workshop* on the topic of Art x Public AI last month, we sketched out an AI tech stack (see above) in order to get a more multi-dimensional view of AI tools that artists are using across their technological infrastructures. In particular, we explored how the tech at each layer is governed and whether or not it is open source. This has been a useful preliminary exercise for shifting the conversation around foundational AI models, from being purely about the IP of inputs (training data) and outputs (generated works), to a bigger one about the interplay between different public and private governance and ownership models used at each layer of the stack. This shift is necessary to give us a better picture of how public interest can be positioned in relation to the influence and development of these technologies.
To this end, Alana Kushnir (Serpentine Legal Lab & Guest Work Agency) provided us with insights into the existing legal frameworks for each layer of the AI tech stack. This allowed us to identify conceptual gaps and speculate about new types of legal and supralegal approaches that might become necessary in the near future. This first attempt to create a method for examining AI tools has allowed us to articulate where new approaches need to be devised––e.g. for dataset governance, or for a model and its weights.
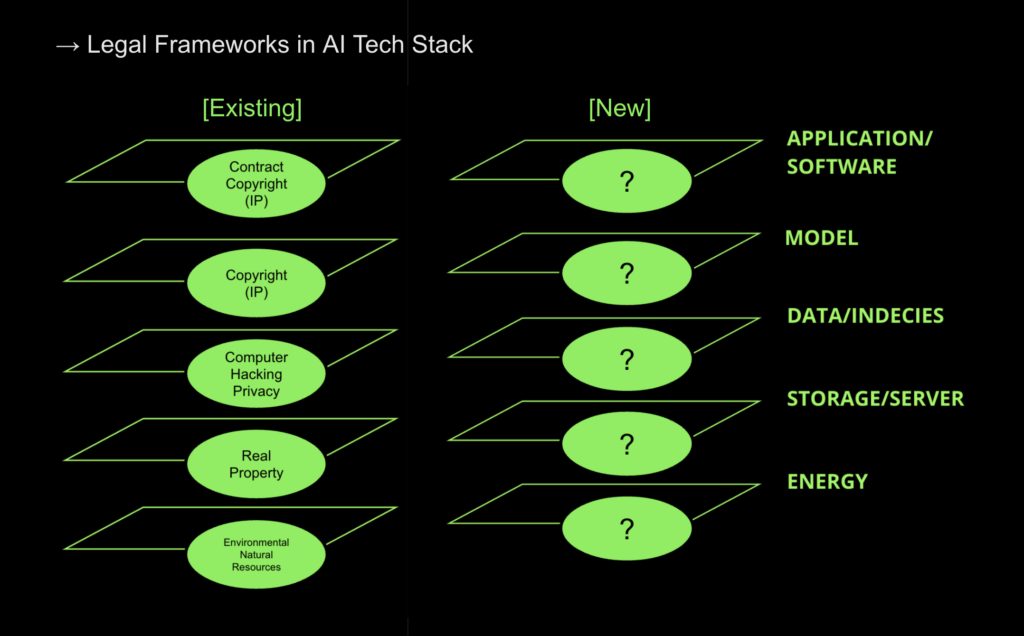
As an example, RadicalxChange’s work on data coalitions and escrow agents presents a new data governance paradigm that could sit within the ‘data’ layer of the stack. New frameworks like this emerge only when we closely interrogate the value of the data layer and understand it to be relational. This aligns well with Salome Viljoen’s work on relational data, which Photini Vrikki and Mercedes Bunz discuss as a shift from big to democratic data.
Why use artistic production to explore AI discourse?
We know from our work in the Creative AI Lab that artistic practices are exceptionally good at surfacing models for engagement with AI technologies–and not only engagement with the end user. More importantly, the production processes of the creative systems (including ML models) that artists build, highlight concerns that are resonant with those of the general public: What rights do you have over the models you build? Or over the outcomes of a model you use? What relationship do you have to the data you use to train it? Etc.
As we move closer to a world where generative images, audio, and language models can produce evocative content ad infinitum, artists will increasingly identify their ‘artwork’ with their own creative tech system including their own AI model. So, for artists working with AI, the capacity for creative agency will be heavily correlated with the ability to manipulate, govern and verify their machine learning models. And as it happens, this negotiation will also be central to the way in which AI can become a truly public societal infrastructure.
We will be posting updates as we advance our research. You can also follow the work of Future Art Ecosystems by subscribing to their newsletter, here.
Eva, Mercedes & the Creative AI Lab
*Thanks to Eva Jäger, Victoria Ivanova and Kay Watson (Serpentine), Alana Kushnir (Serpentine Legal Lab & Guest Work Agency), Reema Selhi (DACS), Oliver Smith (dmstfctn), and Mercedes Bunz, Daniel Chavez Heras, Alasdair Milne (all DDH) as well as Caroline Sinders.